
논문의 원본 링크는 아래와 같습니다.
https://arxiv.org/abs/2205.14135
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to address this problem by trading off model quality to reduce
arxiv.org
1. 개요
트랜스포머 아키텍처는 인공지능 분야에 혁명을 가져왔지만, 그 핵심인 어텐션 메커니즘은 치명적인 비효율성을 안고 있다. 입력 시퀀스 길이가 길어질수록 계산량과 메모리 사용량이 O(N²)으로 폭발적으로 증가하는 문제가 발생한다. 이로 인해 모델의 학습과 추론 속도가 느려지고, 긴 문맥을 처리하는 데 한계가 있었다. 본 논문은 이러한 병목 현상을 해결하기 위해 FlashAttention이라는 새로운 알고리즘을 제안한다. FlashAttention은 어텐션 연산을 IO 인식(IO-Aware) 방식으로 재구성하여 GPU의 메모리 접근을 최소화하고, 기존 트랜스포머의 성능을 획기적으로 향상시킨다.
2. 연구 배경
기존 어텐션 연산은 GPU의 메모리 계층 구조를 비효율적으로 사용한다. GPU에는 빠르고 작은 SRAM과 느리고 큰 HBM(고대역폭 메모리)이 존재한다. 일반적인 어텐션 연산은 데이터를 HBM에서 SRAM으로 옮겨 계산하고, 중간 결과인 어텐션 행렬을 다시 HBM에 저장하는 과정을 반복한다. 이러한 잦은 데이터 전송(I/O)이 모델 속도를 저하시키는 주요 원인이다. FlashAttention은 이 메모리 병목 현상을 해결하기 위해 설계되었다.
3. 실험 설계
논문에서는 FlashAttention의 성능을 입증하기 위해 다양한 실험을 진행했다.
- 속도 측정: BERT, GPT-2 등 여러 트랜스포머 모델의 학습 및 추론 속도를 기존 최적화된 구현체와 비교
- 메모리 효율성: 시퀀스 길이에 따른 메모리 사용량 변화를 분석하여 기존 어텐션과의 차이를 확인
- 모델 품질: FlashAttention 적용 후 성능 저하 여부를 검증하기 위해 언어 모델링(Perplexity), 장문 문서 분류 등의 벤치마크 수행
4. 주요 결과
- 압도적인 속도 향상: 기존 대비 최대 3배 빠른 학습 속도, 2.4배 빠른 추론 속도 달성
- 획기적인 메모리 절약: 메모리 사용량을 시퀀스 길이에 대해 선형적(O(N))으로 감소시켜, 최대 20배 절약 효과 확인
- 정확도 유지: 성능 저하 없이 기존 모델과 동일한 결과를 내며, 근사치가 아닌 정확한 어텐션임을 입증
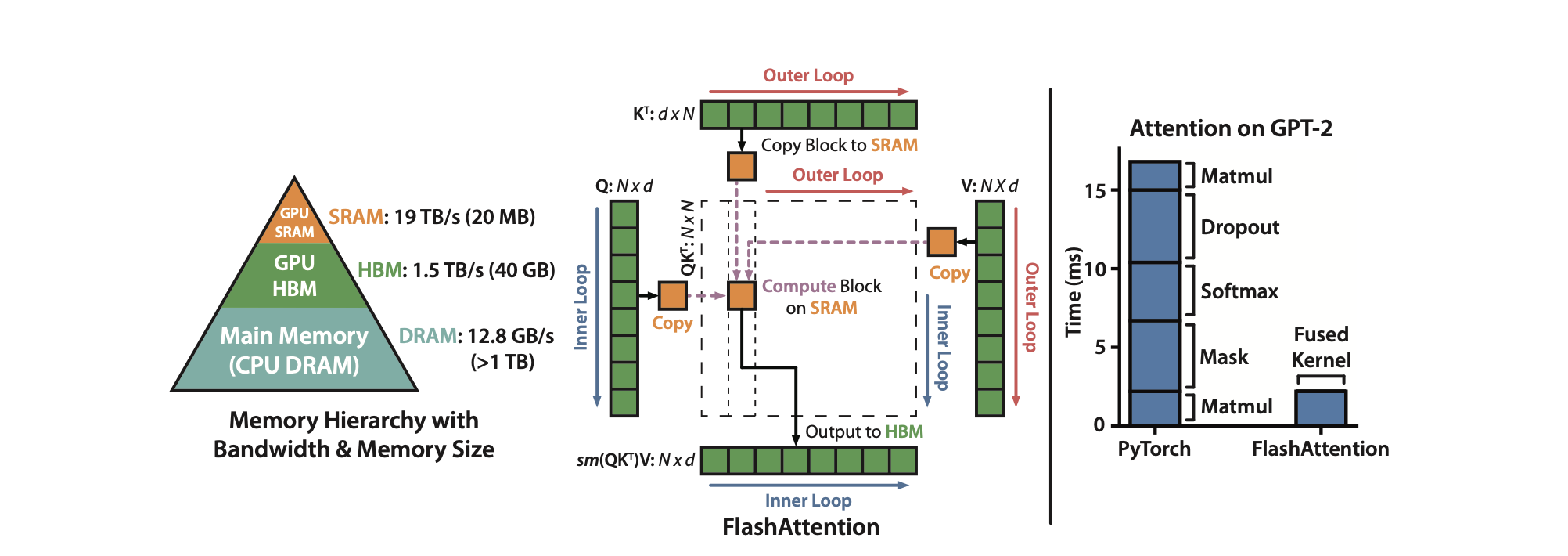
왼쪽 (Memory Hierarchy)
GPU와 CPU 메모리 계층 구조를 보여줍니다.
SRAM (약 20MB, 19TB/s 대역폭) → 아주 빠르지만 용량이 작음
HBM (40GB, 1.5TB/s 대역폭) → GPU 메모리, 속도는 SRAM보다 느림
CPU DRAM (1TB 이상, 12.8GB/s 대역폭) → 용량은 크지만 가장 느림
FlashAttention은 이 계층 구조에서 SRAM 중심으로 계산을 처리해 HBM 접근을 최소화하는 게 핵심입니다.
가운데 (FlashAttention 구조)
전통적인 어텐션은 QK^T, Softmax, V 곱의 중간 결과를 HBM에 계속 읽고 쓰지만,
FlashAttention은 블록 단위 타일링(tiled computation)을 적용하여:
- Q, K, V를 작은 블록으로 잘라 SRAM에 올려놓고 바로 계산
- 중간 어텐션 행렬을 HBM에 저장하지 않고 최종 결과만 HBM에 기록
이를 통해 I/O 병목을 없애고 연산 효율을 극대화합니다.
오른쪽 (성능 비교)
GPT-2에서 어텐션 연산 시간을 비교한 그래프입니다.
PyTorch 기본 어텐션은 Matmul, Mask, Softmax, Dropout 등 여러 커널이 분리되어 실행 → 시간 오래 걸림
FlashAttention은 이들을 하나의 Fused Kernel로 합쳐 실행 → 대폭적인 속도 개선
5. 이론적 해석
FlashAttention의 핵심은 IO 인식 알고리즘이다. 어텐션 연산을 GPU 메모리 계층 구조에 맞게 재정렬하고, 타일링(Tiling)과 재연산(Recomputation) 기법을 활용하여 HBM 접근을 최소화한다. 어텐션 행렬을 HBM에 쓰지 않고 SRAM에서 바로 계산을 마친 후 최종 결과만 저장함으로써, I/O 오버헤드를 근본적으로 줄이는 데 성공했다. 이는 소프트웨어 최적화만으로도 하드웨어 성능을 극대화할 수 있음을 보여주는 사례다.
6. 결론
"FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness" 논문은 트랜스포머의 고질적인 문제를 알고리즘적 혁신으로 해결한 중요한 연구다. 이 기술은 기존 모델의 효율성을 극대화하여 AI 모델의 학습 및 배포를 더욱 빠르고 저렴하게 만들었다. FlashAttention은 현재 LLM 커뮤니티의 필수적인 구성 요소로 자리잡았으며, AI 연구의 발전이 아키텍처뿐 아니라 세밀한 알고리즘 최적화를 통해서도 가능하다는 점을 입증했다.
7. 이외
FlashAttention은 이후 FlashAttention-2, FlashAttention-3로 발전하며, NVIDIA의 최신 GPU 아키텍처(Hopper 등)에 최적화되었다. 이 기술들은 하드웨어의 새로운 기능을 활용해 더욱 높은 연산 효율성을 달성하며, AI 모델 성능을 끌어올리는 데 중요한 역할을 하고 있다.